
起源与发展
模糊测试起源于Barton P. Miller的一次经验:在一次雷雨交加的通话中,雷电导致了一些通信的字符变成了乱码,而这些乱码竟导致了程序的崩溃。于是他就提出了模糊测试。他的技术构想是:
- 核心组件:一组用于产生随机字符的程序
- 中心思想:以随机字符串作为输入,运行操作系统组件,观察是否崩溃
- 最终结果:保留能够产生崩溃的字符串输入,分析崩溃类型,对崩溃进行分类
概念与框架
模糊测试最初的构想中包含三个要素:一个(套)工具——模糊器、一个目标——待测程序、一个循环——执行程序–崩溃分派。
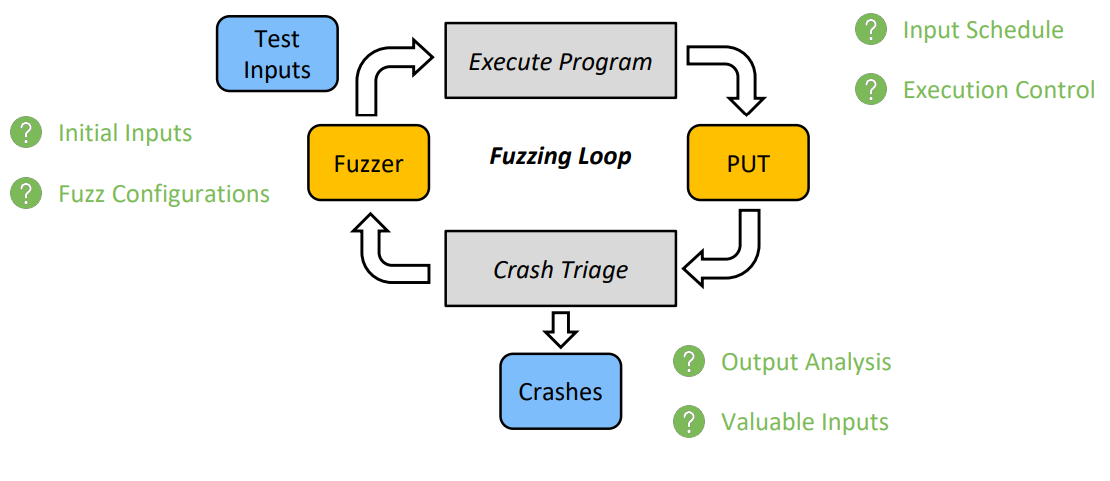
利用模糊器(Fuzzer)产生随机测试用例,然后用这些用例执行待测试程序,如果产生了Error与崩溃,则对其进行分类(如堆栈、输入)。
这种框架缺少很多细节:
- 最初的输入
- 模糊测试的配置
- 如何调度输入(输入的筛选、排序、能量(资源))
- 执行过程控制
- 如何分析输出(很多Bug并没有产生crush)
- 产生的有意义的输入
相关术语:模糊、模糊测试、模糊器、模糊运动、缺陷预言、模糊配置、测试输入、测试用例、种子输入
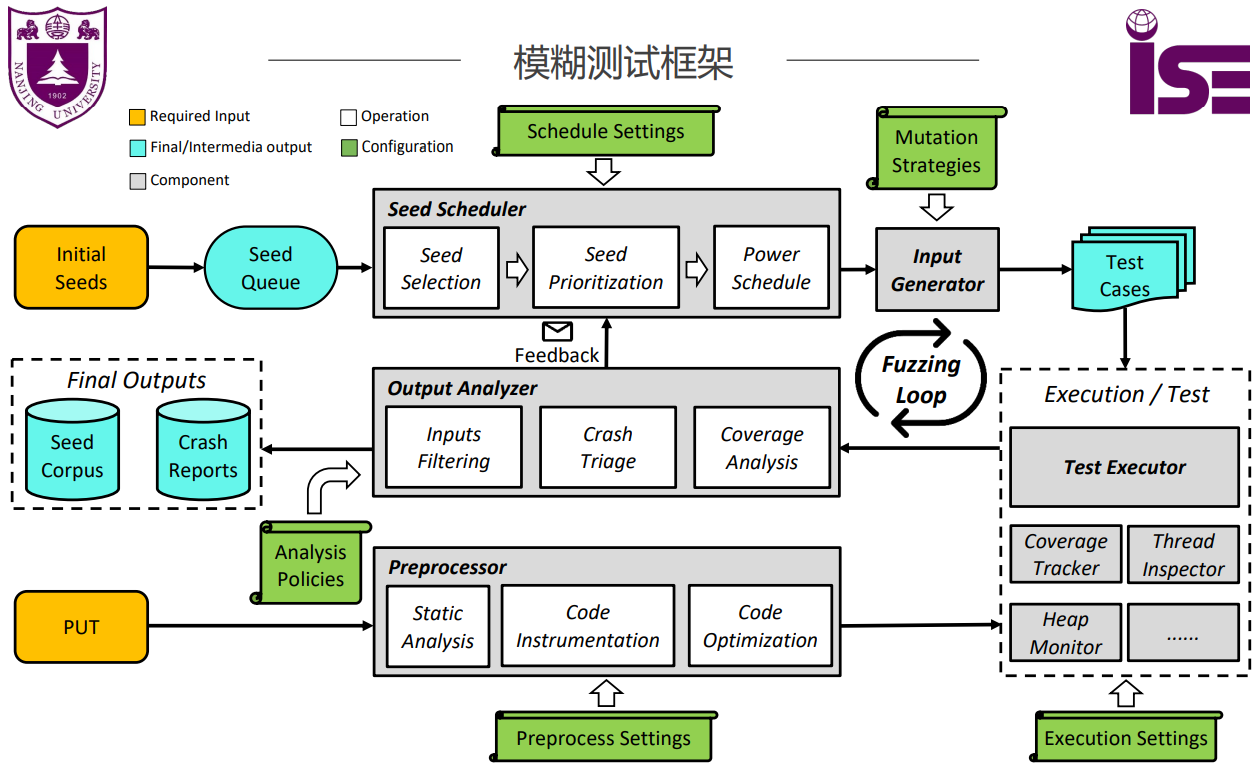
现代的模糊测试框架:
家族与分类
模糊测试框架有很多分类方式。
根据基础Fuzzer划分家族有AFL家族(C、C++)、LibFuzzer家族(C、C++)、JQF家族(Java)、其他(Rust、Python等)。
根据组件核心或技术贡献进行分类:
- 按照采用的运行时信息:黑盒、白盒、灰盒
- 按照输入生成的策略:基于变异、基于生成
- 按照引导过程:启发式算法、梯度下降
- 按照测试目的:定向、非定向、某一类缺陷
- 按照应用领域:网络协议、编译器、DNN、IoT、内核
- 按照优化角度:种子调度、变异策略、能量调度、过程建模
按照运行时信息分类
黑盒测试
- 特点:只从输入输出端入手优化模糊测试。
- 引导方式:利用输入格式和输出状态引导测试执行。
- 优缺点:效率高,但引导的有效性欠缺。
- 代表性工作:KIF、IoTFuzzer、CodeAlchemist
白盒测试
- 特点:使用混合执行、污点分析等静态分析技术
- 引导方式:利用程序分析结果引导测试执行
- 优缺点:反馈更加有效,但效率不高、适配性较差
- 代表性工作:Driller、QSYM、CONFETTI
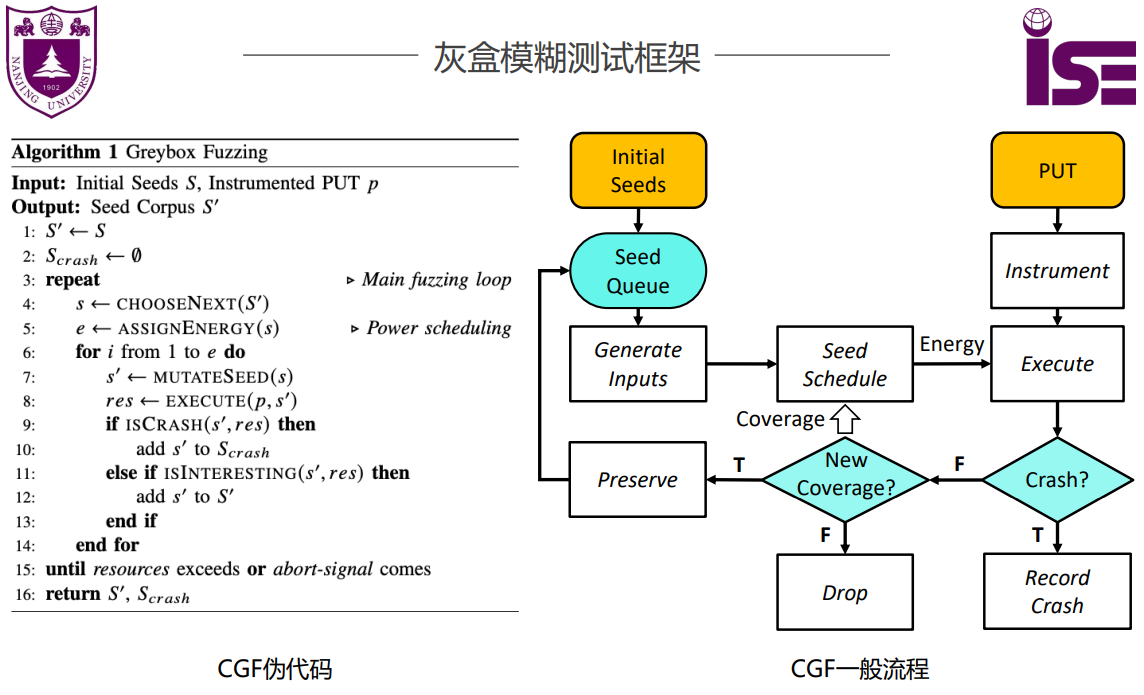
灰盒测试
Coverage-based Greybox Fuzzing, CGF
- 采用轻量级插桩进行监控,收集分支覆盖、线程执行、堆栈状态等信息
- 引导方式:利用收集到的内部状态引导测试执行
- 代表性工作:AFL、AFLGo、EcoFuzz、Zest、BeDivFuzz
按照生成策略分类
Mutation-based
基于随机变异或启发式变异策略
- 本质:将种子输入转换为比特串,对比特串进行变化
- 优点:可拓展性强,易于泛化,理论上可用于各类输入
- 缺点:容易产生无效输入
AFL变异算子:
- bitflip L/S: 以S为增量,每次反转L位
- arith L/8: 加减长度为L的小整数
- interest L/8: 反转“有趣”字节位
- havoc: 对输入进行大肆破坏
- splice: 随机拼接两个种子输入
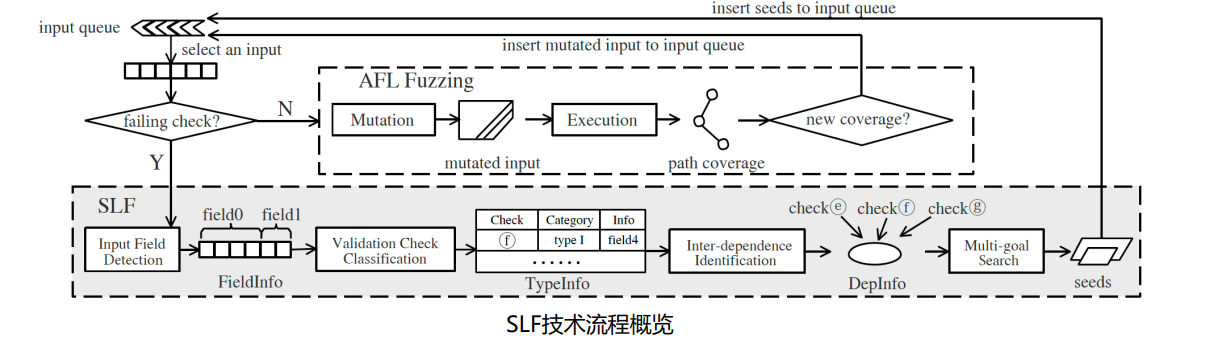
SLF:
- 思想:分析程序中的语义检查,识别和语义检查有关的部分,根据比特串中的域制定变异策略
Generation-based
基于一定的文法规则/结构信息
- 本质:利用得到的文法规则,构建能够通过语法检查的结构化输入
- 优点:容易生成合法、有效输入,适用于对输入结构性要求较高的常见,如解析器、解释器、编译器的测试
- 缺点:需要人工指定领域知识。
Input from Hell:
思想:挖掘已有的测试输入,得到现有的测试用例分布。根据该分布进行输入生成得到预期的测试输入。
-
表示输入的分布:概率文法
-
预期输入
-
与概率文法相同:相似测试输入
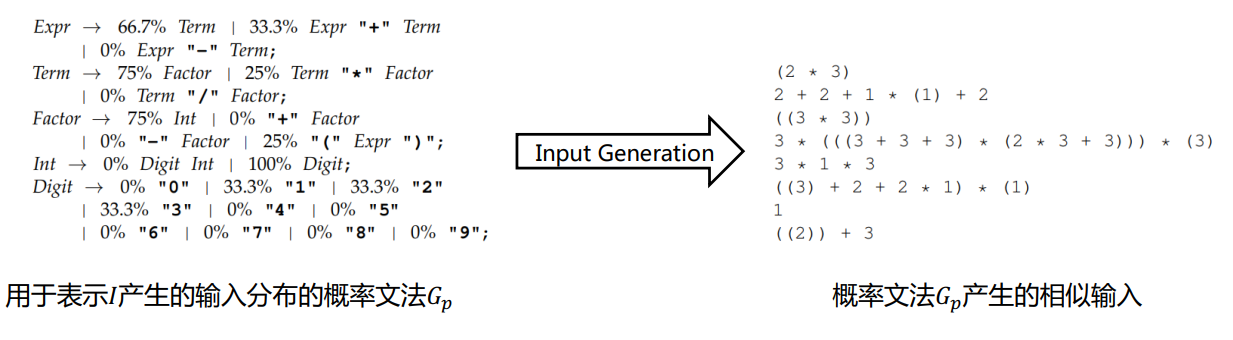
-
与概率文法相反:互补测试输入
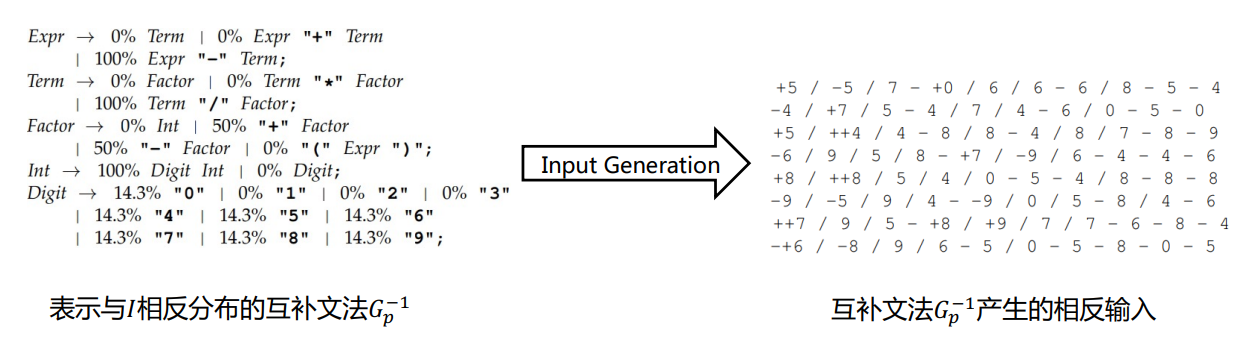
-