
在测试成本过高时,需要通过测试用例优先级策略对测试用例进行排序,以保证最大化的测试效果。
测试用例优先级(TCP)选择策略包括:
- 基于贪心的TCP策略
- 基于相似性的TCP策略
- 基于搜索的TCP策略
- 基于机器学习的TCP策略
基于贪心的TCP策略
全局贪心算法
-
每轮优先挑选覆盖最多代码单元的测试用例
-
多个用例相同则随机选择

额外贪心算法
- 每轮优先挑选覆盖最多,且未被已选择用例覆盖代码单元的测试用例
- 所有代码单元均已被覆盖则重置优先级排序过程
- 多个用例相同则随机选择

例如对于以下的程序:

和以下的测试用例:

使用全局贪心算法的过程:
- t1、t2、t3的覆盖率分别为5/9,4/9,8/9,故排序为t3,t1,t2
使用额外贪心算法的过程:
- 首先t3的覆盖率为8/9,最高,故选择t3
- 其次,对剩下的第四行,t2的覆盖率达到了1/1,故再选择t2
- 由于已全部覆盖,进行重置
- 剩下的t1中,t1的覆盖率达到了其中最高的5/9,故选择t1
- 最终排序为t3,t2,t1
基于相似性的TCP策略
其动机源于缺陷在程序的分布特征:故障通常聚在一起。
自适应随机策略
基本定义:每轮优先选择与已选择测试用例差异最大的测试用例,形成输入域分布均匀的候选测试用例集。然后计算候选测试用例与已排序测试用例集的距离,选择最远者形成排序。
测试用例的距离:
记$U(t_1)$为测试用例$t_1$覆盖的代码单元集合,则测试用例$t_1$和$t_2$的距离为: \(Jaccard(t_1,t_2)=1-\frac{\mid U(t_1)\cap U(t_2)\mid}{\mid U(t_1)\cup U(t_2)\mid}\) 测试用例与测试用例集距离的计算:分别使用最小距离、最大距离、平均距离进行计算
基于搜索的TCP
基本定义:探索用例优先级排序组合的状态空间,找到检测错误更快的用例序列
遗传算法
遗传算法首先生成N个测试用例序列,然后随机选择序列,两两配对,在随机生成的切割点后两两交换(仅交换共性部分)。同时以一定概率选择测试用例序列,随机交换两个测试用例的位置。计算这些变异体的评估值,直至产生评估值最高的序列。
例如初始生成了两个序列,序列内按照以优先级排序:
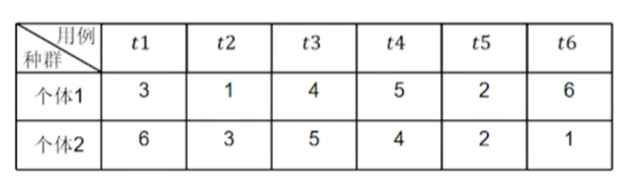
然后随机生成交叉点,在交叉点后进行交换:
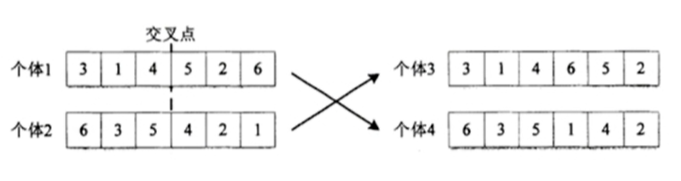
在生成个体3时,个体1保存交叉点前面部分不变,后面部分按照个体2的排序顺序改变位置,个体4同理。
同时还有变异操作:
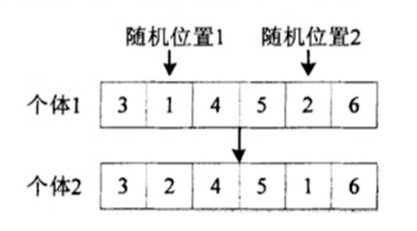
通过交换测试用例顺序产生变异体。
评估值计算:以语句覆盖为例,程序包含m个语句$M={s_1,s_2,…,s_m}$,$T^{‘}$为一个测试用例序列,包含n个测试用例。$TS_i$为第一个覆盖语句$S_i$的测试用例下标,则适应度计算为: \(APSC=1-\frac{TS_1+TS_2+...+TS_m}{n*m}+\frac{1}{2n}\) 显而易见的,越早能将所有语句覆盖的测试用例序列有越高的评估值。
基于机器学习的TCP策略
- 特征提取:设计并提取测试程序中源码特征
- 缺陷模型:建立模型预测测试程序检测缺陷的概率
- 开销模型:建立模型预测测试程序的运行时间
- 测试优先级:基于单位时间内检测缺陷能力进行优先级排序