
概述
多个通过网络互联的计算机都具有一定的计算能力,它们互相传递数据,实现信息共享,协作共同完成一个处理任务
优势:稀有资源实现共享;在多台计算机上平衡负载;将创新放在最适合它的计算机上运行
分布式系统:通过网络消息实现数据通信和协调
分布式计算的一般步骤:设计分布式计算模型;分布式任务分配;编写并执行分布式程序
难点:计算任务划分、多节点通信
理论基础
ACID
原子性、一致性、隔离性、持久性
CAP
一个分布式系统最多同时满足一致性、可用性、分区容错性中的两项
一致性:一次操作后,所有节点同一时间的数据完全一致
可用性:服务一直可用且在正常的响应时间内
分区容错性:分布式系统遇到某节点或网络故障时,仍然能够对外提供一致性和可用性的服务
BASE
BA:基本可用,系统出现故障时,允许部分损失可用性,保证核心可用
S:软状态,允许系统存在中间状态,但中间状态不影响系统的整体可用性
E:最终一致性,经过一段时间后,所有数据副本最终能达到一致的状态
一致性算法
在一个分布式场景中,如果各个节点的初始状态一致,执行相同的指令序列,那么就能达到一个一致性状态。因此需要一致性算法保证每个节点看到的数据一致,
- 一台机器中多个进程/线程保持一致
- 分布式文件系统或者分布式数据库中多客户端并发读写数据
- 分布式存储中多个副本响应读写请求的一致性
Paxos
参与者
提议者Proposer:向其他节点提出提案
- 准备:向其他所有决策者发送提案ID,等待回复
- 收到多数决策者回应后,发送提案value
决策者Accepter:回应提议者的提议
- 如果收到过提议,则将ID和对应的Value返回
- 如果没有收到过提议,则返回空
学习者Learner:不参与决策,知识从决策过程中学习到最终的一致提案的value
过程
- 提议者发准备请求;决策者回应ID和Value,并许下承诺,不再接受ID小于它的提案的提交请求和ID小于等于它的提案的准备请求
- 提议者收到多数回应后,从应答中选择提案ID最大的那个Value作为本次要发起的提案Value,发出带Value的接受请求,如果所有回应都为空,则任意选择一个Value;决策者进行接受处理
- 提议者收到多数回应后,表示提案成功,立刻将决议发送给所有学习者。
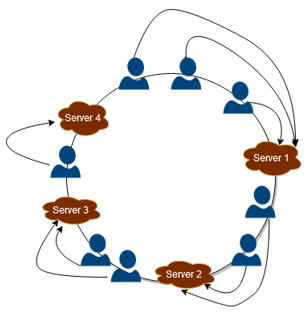
一致性Hash
初始化:计算服务器在环上位置
使用:计算数据在环上位置。随后存储在数据位置延顺时针的下一个服务器位置
类型
存储系统
结构化存储
事务处理系统或关系型数据库,数据划分位表、字段和关系,如分布式MySQL
非结构化存储
强调高扩展性,存储数据自由,典型代表是分布式文件系统,如HDFS、GFS等
半结构化存储
为了解决非结构化存储随机访问性能差的问题,如NoSQL、KV-Store、对象存储
In-Memory存储
基于内存的存储系统,利用内存实现高读写性能,例如Redis,作缓存
NewSQL
既具备结构化存储的ACID,又拥有NoSQL半结构化存储的强大可扩展能力
计算系统
基于消息的系统
MPI(Message Passing Interface)
非常灵活,对应用程序无约束
Dataflow系统
将计算抽象为高层算子,算子组合成有向无环图,由后端调度引擎并行化调度执行。
框架对程序的结构有严格的约束:算子、输入和输出等
Hadoop、MapReduce、Spark:更多类型的算子
流式计算、图计算、分布式机器学习
Spark都有实现。
资源管理系统
Yarn、Apache Mesos、Spark Standalone、Kubernets