
PCA是通过将n维数据选取k个维度来达到降维的效果。选取k个维度,便是在n维空间中选取k个正交的坐标轴,使得原数据在这k个坐标轴上的方差最大,从而在尽可能保留原数据多样性的情况下减少冗余数据量。
PCA降维的步骤:对每个特征中心化;计算协方差矩阵;计算其特征值和特征向量;取前k个特征值和特征向量直到满足降维需要。此时我们便得到了k个坐标轴,对原数据变化到其上就是降维后的数据
Java中代码实现如下:
Instances data=new Instances(new BufferedReader(new FileReader("diabetes.arff")));
data.setClassIndex(data.numAttributes()-1);
PrincipalComponents pca=new PrincipalComponents();
pca.setCenterData(true);
AttributeSelection filter=new AttributeSelection();
filter.setEvaluator(pca);
filter.setInputFormat(data);
filter.setSearch(new Ranker());
Instances useFilter = Filter.useFilter(data, filter);
System.out.println(useFilter);
System.out.println(pca);
首先读取数据,设置最后一列(是否为阳性)为标签(防止被其降维掉)。然后构造PCA分析对象,然后我们设置使用根据协方差而不是相关矩阵进行处理。接下来我们可以根据需要设置覆盖的方差比例。如果为1那么就是取全部的特征值。默认为0.95,即取前k大的特征值至总和的95%。
接下来构造属性选择器(降维器),设置降维算法为pca,使用Ranker进行排序,然后进行降维处理。
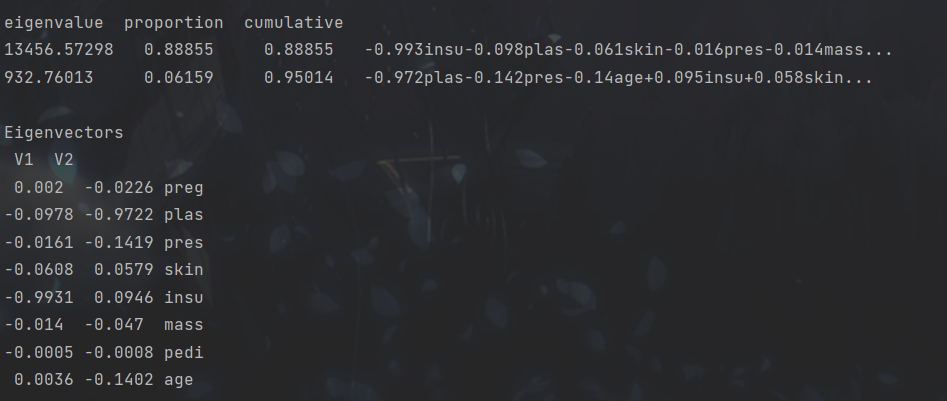
在95%的方差覆盖下,数据被降至两维
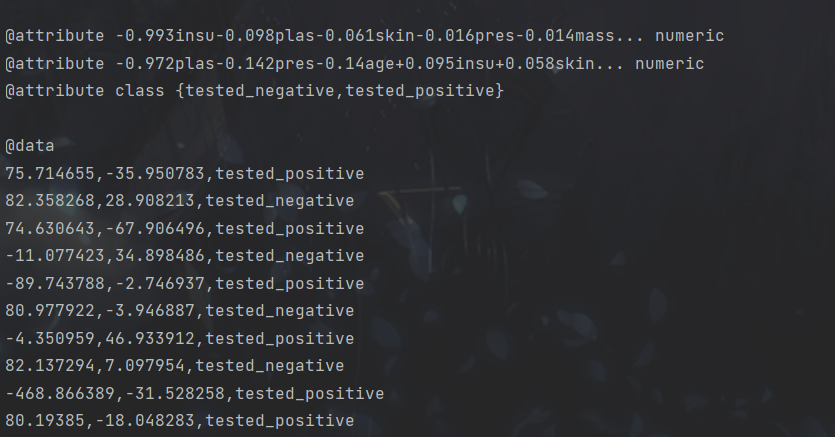
降维效果显著。
如果设置
pca.setVarianceCovered(1)
那么可以看到全部的特征值情况
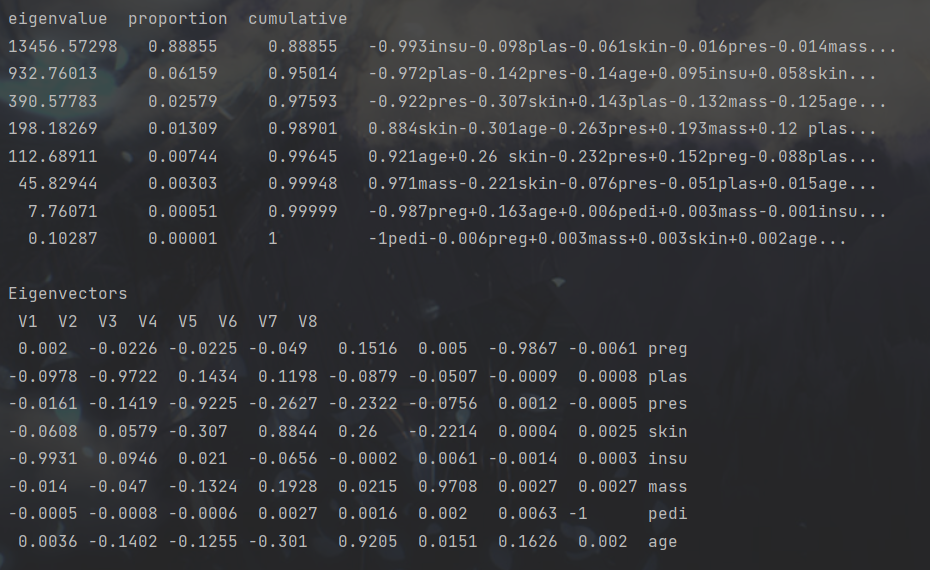
可以看出最后几个特征向量的占比极低,将这些维度的数据剔除后不会产生多大负面影响。